Why Describo? Where does it fit?
Author: Marco La Rosa, 25/7/2024
Summary
Describo is a flexible tool designed for researchers, librarians, and archivists working with text-based content in the early stages of the research data lifecycle. It provides capabilities for data manipulation, AI-assisted analysis, metadata creation, and standardized output, bridging the gap between messy workspaces and structured repositories. While complementary to national data initiatives, Describo focuses on supporting the research process itself, allowing users to work with their data in customized ways while still producing well-described, standards-compliant research objects.
Attribution: I asked the Describo Assistant to summarise this page for me.
I was recently asked whether I had reached out to the ARDC HASS and Indigenous Research Data Commons to see whether there was potential for Describo to become part of a national data platform. I started writing a response but then realised that despite all the content on this website, I hadn't articulated "Why" anyone would actually use Describo and how it relates to broader national initiatives.
In this article I will attempt to answer those questions. Although I'll refer to Australian national initiatives, I believe this applies to all national initiatives around the world.
The Strategy page on the ARDC website describes their mission as "accelerate research and innovation by driving excellence in the creation, analysis and retention of high-quality data assets". To support this mission there are a number of program areas and services to both manipulate data and make it accessible. For example, in the HASS and Indigenous space, this means services like the Language Data Commons and the Indigenous Data Network.
If a research project exists on a continuum spanning from idea to outcome, then these services live on the right hand side of it. That is, they are there to collect and make accessible work that has come from the research process; meaning that whilst the work is happening, it's likely not ready to live in those services.
In reality, the research process and its associated lifecycle is better thought of as a set of interrelated stages.
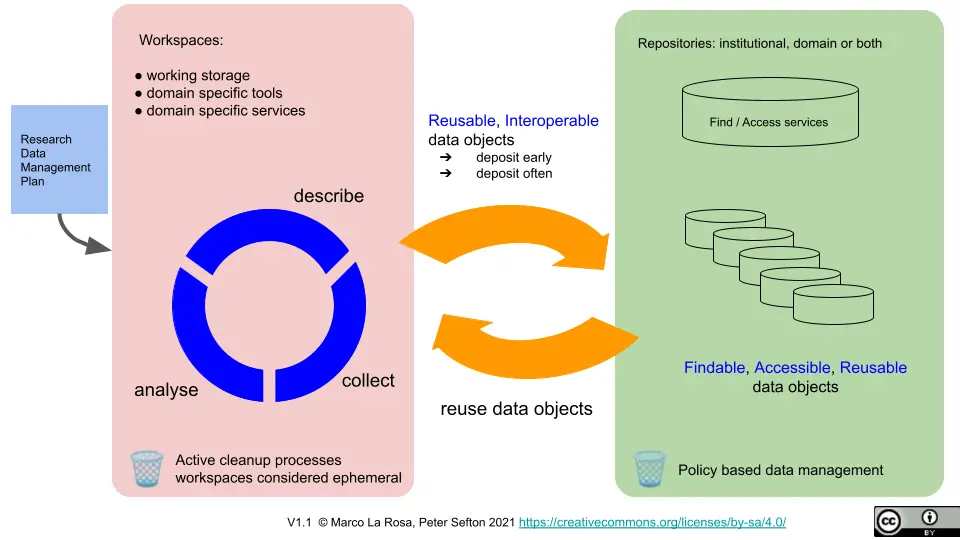
Workspaces
In the image we see Workspaces on the left in that lovely shade of pink. This is where the work is done and it is circular because as one gets to know the problem better, they can then further collect, refine and develop the work; which leads to a better understanding which leads back to collection and on it goes.
Workspaces encompass the tools and services that the user needs to perform their work. Workspaces are messy - just like research is - because they can include anything given that workflows differ by domain and often by user. Some users might have workspaces based on Python Notebooks whilst others just need Microsoft Word. There is no wrong answer on this side of the diagram.
Online / Shared Workspaces
In many domains shared, online workspaces are an important part of the complement of tools available to users provided that the user can upload their data to it given access conditions, ethics requirements etc.
Further on I give an example of how the Nyingarn Project had to navigate issues around a shared, online workspace. Issues that Describo mitigates.
Describo lives here
Describo is for people working with text based content in various formats. It provides tools for them to manipulate their data and transform it; mine it for information using AI tools and cloud services; describe what they're finding as linked data entity relationships; and ultimately, publish their work.
Describo produces data objects in a standardised format: the Research Object Crate (RO-Crate). So, as the work is happening, the user can be sure that they will have a sensible data object as and when it's required.
But Describo doesn't limit what the user can do. That is up to them and it's designed to be flexible enough to adapt to many different use cases as I describe later. Describo is there to help you; not tell you how to work.
Repositories
On the right of the image we have the Repositories. This is where the outputs of the research process go to live when it makes sense to do so. I'm specifically highlighting that last statement because it's a key point to understand. The point at which the process in the middle (Reusable, Interoperable data objects) is triggered depends on the project and the work being done. One size does not fit all. Furthermore, repositories typically have very detailed and specific requirements that must be met for data to be accepted.
Incomplete is ok on this side but messy is not. My colleague Dr Mike Jones recently wrote an excellent article titled Rewilding humanities data that brilliantly parallels data standardisation with the loss of diversity and value lost in tree plantations. I quote:
But, like carefully aligned plantations of trees, there is a danger that the fertility of the system will be shortlived. Stripping away complexity means stripping away much of the meaning, while the wish to remain in control is too often predicated on centralised models of surveillance and the ceding of control to others.
This is especially true on this side of the diagram. Typically, these commons services need to enforce particular requirements in order for them to accept data. Using LDACA as an example that means your data must be an RO-Crate (GOOD); the metadata must meet certain minimum requirements (FINE); should conform to a custom Ontology (AAAARRRGGGGHHHHH!!!!!!).
There is a note at the very top explaining who the audience is but the point I want to make is that this is not atypical of repositories. Specifically, a constrained set of requirements for data acceptance with a high barrier of entry regardless.
ARDC (largely) lives here
Let it be known that I'm not advocating against the work of the ARDC or the funded projects. The work that is being done is A Good Thing™ but that doesn't mean that we shouldn't be aware of the compromises required to achieve the goal.
So how does Describo relate to the national initiatives?
In short: it's complementary.
Describo's target audience is the librarian, archivist, historian who is working to make sense of text based content. They want to understand it; describe it; reason about it; and finally, make the results of their efforts - their scholarship - available to a wider audience. For this user Describo offers tools to help them in their workflow as described in the next section. And its flexibility allows them to do the messy work of research in the way that suits them.
Describo is complementary to the national programs because in the end, the user is left with a research data object that is well described, in standard metadata supported by those initiatives.
Whilst being complementary to the national initiatives, at this time, Describo is not a part of them. My hope is that in time this will change.
Describo Persona's
We now know where Describo fits into the landscape so let's consider why anyone would want to use it.
What's in the box?

The problem statement:
You are an archivist or historian. When confronted with a literal box full of files, you might identify with the following:
As an archivist you will likely digitise each individual file using a compressionless format like TIFF. But, as it's not a great format for dissemination you will then produce web accessible formats as well.
As a historian you will probably sift through the contents looking for information that is useful in your area of research. You may digitise those documents of interest to take away and perform further analysis on.
In both cases, the next step involves understanding the content. Who does it talk about? What are they discussing? Why are they discussing it? What relationships can we uncover from the documents? You will meticulously read, consider and annotate each and every document in the set, carefully creating the data structures you need to answer the questions you have.
As an archivist you will likely produce a finding aid to support discovery of the content whist as a historian you may use the descriptions you created to link the content into your field of work.
When you're done, you may write some metadata capturing your scholarship and publish it alongside your work. Then, you'll deposit your research into a repository of some kind.
And of course, maybe you weren't 'gifted' the box of materials. Maybe you just emerged from the archives with 2000 images on your phone and your eyes squinting from exposure to sunlight!
How Describo can help:
Describo has been specifically crafted to help with these processes. There are tools to batch transform digitised content (e.g. produce thumbnails and webformats); services that can transcribe and markup the entities described; an assistant to help you quickly understand what is contained in batches of content and a visualisation tool to inspect the information you've created around the data. In the end, you will have a specification compliant RO-Crate that you can then take to repositories for deposit.
What's in the book?

The problem statement:
As we found in the Nyingarn Project, a common refrain from the institutions holding language manuscripts was "We can't make the manuscript available because we need permission to do so. But we don't know what's in it so we can't identify who to ask". The Nyingarn Project was setup to handle exactly this issue - providing tools for people to transcribe, inspect, describe and understand Indigenous language manuscripts in order to provide access to its communities. Yet some of the institutions were concerned with even putting the manuscript into the private workspace where their questions could be answered.
Learn more: The New Protectionism: Risk Aversion and Access to Indigenous Heritage Records
How Describo can help:
As a local (desktop) application, institutional staff could use Describo to transcribe, annotate and describe a manuscript, page by page, without the content ever leaving their computer. However, subject to appropriate permissions being sought, they could also use the cloud services to accelerate that process as they have been specifically designed and architected with data privacy in mind. To read more about that see: How is data handled inside Describo?
I don't know what I don't know

The problem statement:
I'm yet to meet someone who would view the image as a great way to spend 4 days of their life. That said, on a planet with some 8 billion people, statistically speaking, there must be at least a few who would find that exciting. I'm not judging. It's just that for everyone else, how do you come to terms with a set of complex and lengthy documents? How do you a) come to terms with the overall structure of the content, and then b) determine whether the information contained captures all that needs to be captured?
How Describo can help:
With an AI Assistant capable of reading hundreds of pages of text in a few seconds, finding information has never been easier. As the interface is conversational (natural language conversation back and forth), the assistant evolves along with your understanding of the content so as to pinpoint exactly the information you are looking for and help you find what it is that you don't yet know.
Hopefully this article has made clear the space that Describo aims to fill. If you have any questions or comments, please start a conversation below!